LoRAのお試し

LoRAの環境作成と試運転
Git
これらをインストール済みなことを前提とします。
※Pythonのバージョンは必ず守ってください。最新版とか3.11.とかは駄目です。
この記事では、
・学習環境のセットアップ
・テスト学習
・作成したLoRAを使った画像生成
を順番に案内します。
ネットを検索すると、簡単にセットアップ出来るBATファイルなどが配布されているので、面倒なことをしたくない場合、そちらを利用されるのが良いと思います。ぶっちゃけ手作業導入は難解で面倒なので全くおすすめできません。ちんぷんかんぷんです。
ざっくりLoRAって何?
お絵描きAIに、まだ知らないキャラクターなどを教えてあげる追加学習の一種です(意訳)。VRAMが少な目なグラフィックボードでも利用可能なので人気です。
お絵描きAIチェックポイントファイルとLoRA学習済みファイルを組み合わせて使い、学習させたキャラクターのイラストを生成します。
LoRA学習環境準備
学習用サンプルデータのダウンロードと解凍
LoRA学習用サンプルデータ
https://note.com/kohya_ss/n/nb20c5187e15a
こちらから
lora_train_sample_pack.zip
をダウンロードして、任意のフォルダに解凍する。
例 C:\SD\lora_train_sample_pack\
学習用スクリプトのダウンロードと環境設定
次いで、kohya-ss / sd-scripts
https://github.com/kohya-ss/sd-scripts/blob/main/README-ja.md
こちらの手順に従って、GitHubから学習用スクリプトをダウンロードするのですが、説明不足で初心者にはまず無理なので、以下に手順と補足を記します。
コマンドプロンプトを起動する
さきほど解凍したlora_train_sample_packフォルダを開いて、アドレスバーにcmdと入力してENTER。
(※アドレスバー左端のフォルダのアイコンをクリックすると文字入力が出来ます)

コマンドプロンプト(黒いウィンドウ)が起動するので、ここに以降のコマンドを入力していきます。

学習スクリプトの環境設定
上記テキストを選択し、右クリック>コピー。コマンドプロンプト(黒いウィンドウ)で右クリック>Paste、と選択し、テキストを貼り付け、ENTERキーを押す。(※以降「コピペ」と略します)
すると、sd-scripts というフォルダが作成され、学習用スクリプトファイルがダウンロードされます。

続けて、環境の構築を行います。以下の水色ハイライトのコマンドをコピペ、実行していきます。
※やたらと隙間が空いて見えますが、実際には半角スペース1個分です。コピペ操作には支障は無いようです。
cd sd-scripts
とコピペしてENTER。作業位置(カレントディレクトリと言います)がsd-scriptsフォルダへ移動します。
python -m venv venv
pythonの仮想環境を作成します。\sd-scripts\venv、というフォルダが作成されます。
.\venv\Scripts\activate
このコマンドで、これ以降のコマンドを実行するための、python仮想環境を有効化します。
次いで、以下のコマンドを一つずつ順番にコピペして実行してください。ダウンロードとインストールが発生するので、それなりに時間がかかります。
(※詳細は分かりませんが、やれと言われているのでとりあえずやるのです。)
1.
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
2.
pip install --upgrade -r requirements.txt
3.
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
4.
copy /y .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
5.
copy /y .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
6.
copy /y .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
7. 次のコマンドでは質問に答えて設定ファイルを作成します。
回答には数字キーの 0、1、2~で*印を項目に合わせて選択してENTERキーで決定、
または、yes、NO、allと文字入力してENTERという操作をします。
日本語入力(IME)を有効にしないでください。
間違えたり、エラーなどで最後まで進めなかった場合は、ここ(7.)からやり直してください。
accelerate config
In which compute environment are you running?
* This machine
AWS (Amazon SageMaker)
0
Which type of machine are you using?
* No distributed training
multi-CPU
multi-GPU
TPU
MPS
0
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]
NO
Do you wish to optimize your script with troch dynamo? [yes/NO]
NO
Do you want to use DeepSpeed? [yes/NO]
NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]
all
allと回答して駄目っぽい場合には、 0 (ゼロ)と回答する。
Do you wish to use FP16 or BF16 (mixed precision)?
no
* fp16
bf16
1
1を入力すると*印がfp16にフォーカスするのでENTER。
※表示がバグってfp166になりますが大丈夫です。
~回答ここまで。

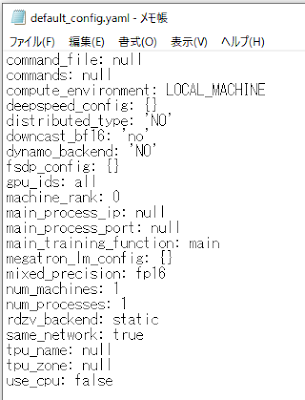
accelerate configuration saved at C:\Users\ユーザー名/.cache\huggingface\accelerate\default_config.yaml
C:\Users\ユーザー名\.cache\huggingface\accelerate\default_config.yaml
というファイルに設定が保存されます。
環境の設定はここまでです。お疲れ様です。
以降、コマンドプロンプトはそのままでも、学習サンプルのテストを続けられます。
一端終了させるには、
deactivate
venv環境を終了して、コマンドプロンプトに戻る。
exit
コマンドプロンプトを終了してウィンドウを閉じる。
~と、操作します。単に右上×ボタンでウィンドウを閉じても大丈夫です。
学習テスト
学習用サンプルを使っての学習テスト
こちらの記事に沿って学習テストを行います。
用意されている学習用pythonスクリプトの種類
train_db.py …… DreamBooth用
fine_tune.py …… FineTuning用
train_textual_inversion.py …… Txtual Inversion用
train_network.py …… LoRA用
sd-scriptsには、いろいろな学習用スクリプト等が同梱されていますが、ここで扱うのはLoRA用の train_network.py です。
また、LoRA学習には、DreamBooth方式 と FineTuning方式 が利用できます(ややこしい)。
この学習サンプルは、LoRA の DreamBooth方式 での学習をします。
AIに覚えてほしい画像(学習用画像、教師画像)

に入っている鳥獣戯画のカエルのイラスト15枚が学習させたいキャラクターです。
フォルダ名の頭の20が繰り返し回数、中身が15枚なので15*20=300stepになります(多分)。
usu は特に意味を持たない単語で、識別子(identifier)として機能します。
(※日本には臼(うす)があるため、usu を識別子に使うのは、もしかしたら不適切かも?)
frogが正則化のクラスで、覚えさせたい要素のざっくりとしたくくり、グループ名です。
例えば女の子のキャラクターを覚えさせたい場合は、20_usu girl といったフォルダ名にします。
正則化画像

C:\SD\lora\lora_train_sample_pack\train\1_frog
に入っているカエルの画像50枚が正則化画像です。
フォルダ名の頭の1が繰り返し回数、frogが正則化のクラス(class)です。
例えば女の子のキャラクターを覚えさせたい場合は、10_girl といったフォルダ名にします。
繰り返し1回、中身が50枚なので50*1=50stepになります(多分)。
step数は、教師≧正則化 とするように指示されています。(適当でも行けます)
エポック ( --max_train_epochs n )
フォルダに表記した繰り返し数とは別に、学習全体を何回繰り返すかを決めるのがエポックの値です。後述の学習実行コマンドのオプションで指定します。
コマンドプロンプトの実行
例 C:\SD\lora_train_sample_pack\sd-scripts
このフォルダで、アドレスバーにcmd、と入力してコマンドプロンプトを起動します。


.\venv\Scripts\activate
とコピペして、python仮想環境を有効化します。

学習実行
下記のクソ長コマンドの model.ckpt の部分を学習に使いたいチェックポイントファイルのフルパスに書き換えます。
お手持ちのテキストエディタや、Googleドキュメントにコピペして編集してください。
例
--pretrained_model_name_or_path="C:\SD\stable-diffusion-webui\models\Stable-diffusion\7th_anime_v2_G_fp16.safetensors"
accelerate launch --num_cpu_threads_per_process 4 train_network.py --pretrained_model_name_or_path=..\model.ckpt --train_data_dir=..\train --reg_data_dir=..\reg --prior_loss_weight=1.0 --resolution 512 --output_dir=..\lora_output --output_name=cjgg_frog --train_batch_size=2 --learning_rate=1e-4 --max_train_epochs 4 --use_8bit_adam --xformers --mixed_precision=fp16 --save_precision=fp16 --seed 42 --save_model_as=safetensors --save_every_n_epochs=1 --max_data_loader_n_workers=1 --network_module=networks.lora --network_dim=4 --training_comment="activate by usu frog"
コマンドプロンプトにコピペして実行すると学習が始まります。
グラフィックボードのVRAMが足りない場合は --train_batch_size=2 の数値を1に下げます。それでも足りない場合は、--resolution 512 を448、384、256など16の倍数で下げれば動くかもしれません。が、おそらく学習結果の品質は低下します。
学習終了
C:\SD\lora_train_sample_pack\lora_output
というフォルダが作られて、学習したLoRAファイルが保存されています。

学習ファイルを使って画像を生成する
LoRA学習ファイル、 cjgg_frog.safetensors を
例
C:\SD\stable-diffusion-webui\models\Lora
に配置します。
Automatic1111WebUIを起動します。
花札のアイコンをクリックして、学習ファイルの選択メニューを表示します。

Promptの欄にカーソルをフォーカスしてから、LoRAのタブからcjgg_frog.safetensorsをクリックすると、Promptの欄に、
<lora:cjgg_frog:1>
と入力されます。
続けて、 usu frog と入力します。
<lora:cjgg_frog:1>usu frog
として、Generate。
鳥獣戯画っぽいカエルが出てくれば学習出来ていることが確認できます。

Tips
学習効果の強弱
<lora:cjgg_frog:1>
の末尾の数値 1 は適用の強度です。プロンプトと同様にCtrl+カーソル上下で増減が出来ます。
学習が強すぎると感じたら0.7等に下げ、効果が薄いと感じたら1.3等に上げて効き具合を調整できます。
サムネイル登録
生成した画像の一つをクリックして、選択した状態で、LoRA選択リストのファイル名にカーソルを合わせると、サムネイルを登録するか赤字メッセージが表示されるので、クリックすると、選択している画像がサムネイルとして登録されます。更新も同様。間違えて誤登録しやすいので注意です。
以上で学習サンプルの実習は終了です。
お疲れさまでした。
LoRA実践編(手抜き)
accelerate launch --num_cpu_threads_per_process 4 train_network.py
--seed 42
--pretrained_model_name_or_path=..\model.ckpt
--train_data_dir=..\train
--reg_data_dir=..\reg
--prior_loss_weight=1.0
--resolution 512
--output_dir=..\lora_output --output_name=cjgg_frog
--save_model_as=safetensors --save_every_n_epochs=1
--train_batch_size=2 --max_train_epochs 10
--xformers --mixed_precision=fp16 --save_precision=fp16
--max_data_loader_n_workers=1
--network_module=networks.lora
--network_dim=64 --network_alpha=32
--clip_skip=2
--training_comment="activate by usu frog"
--enable_bucket --min_bucket_reso=512 --max_bucket_reso=1280
--optimizer_type=adafactor --optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"
--use_8bit_adam
--learning_rate=1e-4
--network_weights="C:\SD\stable-diffusion-webui\models\Lora\base_lora.safetensors"
上記コマンドをGoogleドキュメント等にコピペして編集します。
行の最後には半角スペースがあります。編集中に削除しないように注意してください。
コマンドのオプションの頭の書き方は半角の、
スペース、マイナス、マイナス
となっています。
コマンドの編集
--pretrained_model_name_or_path=..\model.ckpt
学習のベースにするチェックポイントファイルのフルパスに書き換えます。
例
--pretrained_model_name_or_path="C:\SD\stable-diffusion-webui\models\Stable-diffusion\7th_anime_3.1_C-pruned-fp16.safetensors"
--output_dir=..\lora_output --output_name=cjgg_frog
cjgg_frog の部分が出力ファイル名になります。学習させるキャラクター名などに変更します。
--resolution 512
任意サイズの画像での学習 --resolution 448,640 (幅、高さ)
任意の画像サイズで学習したい場合は --resolution 512 を書き換えます。
768等、数値を高くすると画質は良くなるが、物理メモリとVRAMが要求されるようです(エアプ)。
--train_batch_size=2
VRAMの消費量と相談して数値を決めます。VRAMに余裕があれば上げます。無ければ下げます。VRAM12GBでの目安、1~4。
--max_train_epochs 10
学習の繰り返し数。
--network_dim=64 --network_alpha=32
dim … 64とか128とか。dimの数値が大きいと出来上がるファイルサイズも大きくなります。
alpha … dimと同じ数値、dimの半分、1の三択。よくわからない。
--clip_skip=2
生成時に設定している数値と合わせる。まぁだいたい2です。
--training_comment="activate by usu frog"
コメント。呼び出し用のプロンプトを書いておけば便利かも。
--enable_bucket --min_bucket_reso=512 --max_bucket_reso=1280
このオプションを使うと、教師画像のサイズを揃えなくても良い。
--optimizer_type=adafactor --optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"
--learning_rate=1.0
学習率を良い感じに自動調整する設定。このオプションを使う場合は、Learning Rateを1前後に設定する。例えば 1.0、1.5、など。
--optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True" は不要という説もあります。
--use_8bit_adam
--learning_rate=1e-4
--use_8bit_adam を指定する場合の学習率。覚えが悪い場合に5e-4など高くしてみるといいかも。謎。
--optimizer_type=adafactor と --use_8bit_adam とは同時に指定が出来ないのでどちらかを指定する。
--network_weights="C:\SD\stable-diffusion-webui\models\Lora\base_lora.safetensors"
学習済みのLoRAファイルをベースに学習を追加する場合にこのオプションを指定する。ファイルパスは元にするLoRAファイルのパスに書き換えてください。
編集したコマンドを一行にまとめる

コピペして実行できるように改行を削除して、一行にします。
Googleドキュメントにて。
編集>検索と置換(Ctrl+H)。
「検索」に \n と半角英数字で入力。
※入力は ¥ で、出てくる文字は \ バックスラッシュになりますがそれでOKです。
「次に変更」には何も入力しない。
「正規表現を使用する」をチェックする。
すると、全ての行終りがハイライト表示され、検索で認識されていることが分かります。
「すべて置換」をクリック。
これで、改行が削除され、一行に変換されます。
選択してコピー。
Ctrl+A、Ctrl+C。
コマンドプロンプトにペースト。
Ctrl+V、で実行されます。
例
accelerate launch --num_cpu_threads_per_process 4 train_network.py --seed 42 --pretrained_model_name_or_path=..\model.ckpt --train_data_dir=..\train --reg_data_dir=..\reg --prior_loss_weight=1.0 --resolution 512 --output_dir=..\lora_output --output_name=my_lora --save_model_as=safetensors --save_every_n_epochs=1 --train_batch_size=2 --learning_rate=1.0 --max_train_epochs 10 --xformers --mixed_precision=fp16 --save_precision=fp16 --max_data_loader_n_workers=1 --network_module=networks.lora --network_dim=64 --network_alpha=32 --clip_skip=2 --training_comment="activate by my_lora" --enable_bucket --min_bucket_reso=512 --max_bucket_reso=1280 --optimizer_type=adafactor --optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True" --network_weights="C:\SD\stable-diffusion-webui\models\Lora\base_lora.safetensors"
とりあえずはこんな感じです。
ざっくりキャラLoRA作成方法

教師画像の用意

タグテキストファイルの用意



例 C:\SD\lora_train_sample_pack\train\
学習実行コマンド
例 C:\SD\lora_train_sample_pack\sd-scripts で、
cmd
.\venv\Scripts\activate
accelerate launch ^
--num_cpu_threads_per_process 4 train_network.py ^
--train_data_dir=..\train ^
--prior_loss_weight=1.0 ^
--output_dir=..\lora_output ^
--xformers --mixed_precision=fp16 --save_precision=fp16 ^
--seed 42 --save_model_as=safetensors --save_every_n_epochs=1 ^
--max_data_loader_n_workers=1 ^
--network_module=networks.lora ^
--color_aug ^
--persistent_data_loader_workers ^
--keep_tokens=1 --shuffle_caption ^
--caption_extension=.txt ^
--clip_skip=2 ^
--optimizer_type=adafactor --learning_rate=1.0 ^
--lr_scheduler=cosine_with_restarts ^
--enable_bucket --min_bucket_reso=256 --max_bucket_reso=1280 ^
--pretrained_model_name_or_path="C:\SD\stable-diffusion-webui\models\Stable-diffusion\7th_anime_3.1_C-pruned-fp16.safetensors" ^
--resolution 512 ^
--train_batch_size=2 ^
--max_train_epochs 5 ^
--network_dim=64 --network_alpha=32 ^
--output_name="koropoya_lora" ^
--training_comment="activate by koropoya girl"
他のオプション
既存LoRAファイルに追加学習する場合の例
--network_weights="C:\SD\stable-diffusion-webui\models\Lora\base_lora.safetensors" ^
正則化画像を使う場合の例
--reg_data_dir=..\reg ^

regフォルダに 2_girl のようなサブフォルダを作り、入れておきます。
STEP数(繰り返し数*枚数)は学習キャラクターのそれの10~20%程度にしていますが、設定値に根拠は無いです。
上図の正則化画像を使った場合、絵柄、黒髪、現代的な背景ロケーションの影響が強く出ると思います。
LoRAを使う
LoRAファイルを指定して、タグテキスト作成時に追加したキャラ名の単語をプロンプトに書くとキャラが出てきます。
例 <lora:koropoya:0.55> koropoya, 1girl, solo, maid outfit, ...




0 件のコメント:
コメントを投稿